Abstract
Real-world reinforcement learning (RL) offers a promising approach to training precise and dexterous robotic manipulation policies in an online manner, enabling robots to learn from their own experience while gradually reducing human labor. However, prior real-world RL methods often assume that human interventions are optimal across the entire state space, overlooking the fact that even expert operators cannot consistently provide optimal actions in all states or completely avoid mistakes. Na¨ıvely incorporating intervention data into the RL objective suffers from low sample efficiency, while purely imitating intervention actions can ultimately degrade the final performance achievable by RL. The question of how to leverage potentially suboptimal and noisy human interventions to accelerate learning without being constrained by them thus remains open. To address this challenge, we propose SiLRI, a state-wise Lagrangian reinforcement learning algorithm for real-world robot manipu- lation tasks. Specifically, we formulate the online manipulation problem as a constrained RL optimization, where the constraint bound at each state is determined by the uncertainty of human interventions. We then introduce a state-wise Lagrange multiplier and solve the constraint problem via a min-max optimization, jointly optimizing the policy and the Lagrange multiplier to reach a saddle point. Built upon a human-as-copilot teleoperation system, our algorithm is evaluated through real-world experi- ments on diverse manipulation tasks. Experimental results show that SiLRI effectively exploits human suboptimal interventions, reducing the time required to reach a 90% success rate by at least 50% compared with the state-of-the-art RL method HIL- SERL, and enabling stable success on a challenging dual-arm manipulation task where other RL methods fail.
Method
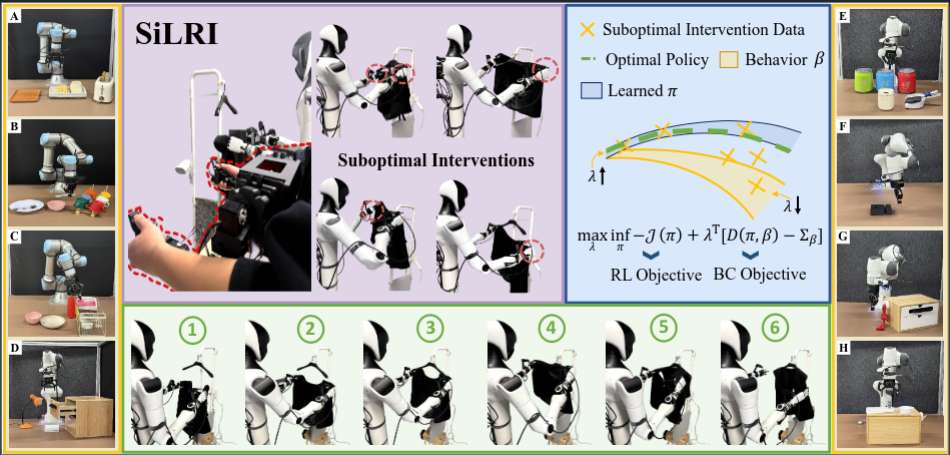
SiLRI Enables Effective Real-world RL from Suboptimal Interventions. Seamless human intervention is provided via a teleoperation system, though interventions can be suboptimal (e.g., inconsistent actions in the same state; purple). SiLRI uses state-wise Lagrange multipliers to adaptively balance the RL and BC objectives (blue), enabling efficient online training on a dual-arm humanoid robot (green) and two other embodiments (yellow, A-H), with training time from 0.5 to 2.5 hours.
Experiments
We design 8 real-world manipulation tasks covering mixed skills, articulated-object manipulation, precise manipulation, and deformable-object handling. These tasks include: (A) Pick-Place Bread (B) Pick-up Spoon (C) Fold Rag (D) Open Cabinet (E) Close Trashbin (F) Push-T (G) Hang Chinese Knot (H) Insert USB. We compare SiLRI with three baseline methods: HIL-SERL, ConRFT, and HG-Dagger. We deliberately introduce external disturbances to examine the robustness and failure recovery ability of each method in four tasks to evaluate the robustness of SiLRI.
Close Trashbin
Push-T
Hang Chinese Knot
Insert USB
Conclusion
In this work, we propose a state-wise Lagrangian reinforcement learning (RL) algorithm from suboptimal interventions, for real-world robot manipulation training. Observing the fact that human operators have different confidence level and manipulation skill over different states, a state-dependent constraint is added to the RL objective to automatically adjust the distance between human policy and learned policy. Building on a human-as-copilot teleoperation system, we evaluate our method with other SOTA online RL and imitation learning methods on 9 manipulation tasks on 3 embodiments. Experimental results show the efficiency of SiLRI to utilize the suboptimal interventions at the beginning of training and converge to a high success rate at the end. Other ablation studies and investigation experiments also conducted to learn the advantage of SiLRI.